モーショノロジー2012 #1: rroongaによる検索サービスの実装
注意: 長いです。
簡単まとめ: 検索サービスを作るにはrroongaが便利です。groongaサポートサービスをはじめます。
CROOZ株式会社が主催する「モーショノロジー2012 #1 全文検索&検索を利用したサービスの使命、利用プロダクト、事例紹介」が開催されました。今回のテーマは検索ということでgroonga開発チームに声をかけてもらいました。groonga関連の枠がいくつかあったのですが、ここではRubyとgroongaを使った検索サービスの作り方についての枠の内容を紹介します。

以下、多少省略しながらスライドの内容を紹介します。
概要

紹介する内容はrroongaを使った場合のメリット・デメリットと入力補完についてです。メリットは事例も交えながら紹介します。入力補完は「Ruby + groongaだからできる」という機能ではなくgroonga単体でも利用できる機能なのですが、最近の検索サービスでは当たり前になっている大事な機能なので、あわせて紹介します。
rroonga?

Rubyとgroongaを一緒に使う方法には以下の2つの方法があります。
- groongaサーバーを起動し、HTTPで通信してgroongaの機能を使う方法
- groongaをライブラリとして使用し、API経由でgroongaの機能を使う方法
全文検索システムはgroonga以外にもたくさんありますが、その中にSolrという全文検索システムがあります。Solrは全文検索エンジンとしてLuceneを利用したシステムです。groongaはLuceneと同じ全文検索エンジン機能もSolrと同じサーバー機能も備えています。groongaサーバーを起動する使い方はSolrのように使う使い方で、ライブラリとして使う使い方はLuceneのように使う使い方になります。
今回は後者のgroongaをライブラリとして使用する方法でのメリット・デメリットを事例を交えながら紹介します。
Rubyからgroongaをライブラリとして使うためにはrroongaというRubyのライブラリを使います。この方法ではアプリケーションがデータベースを持つことになります。
システム構成
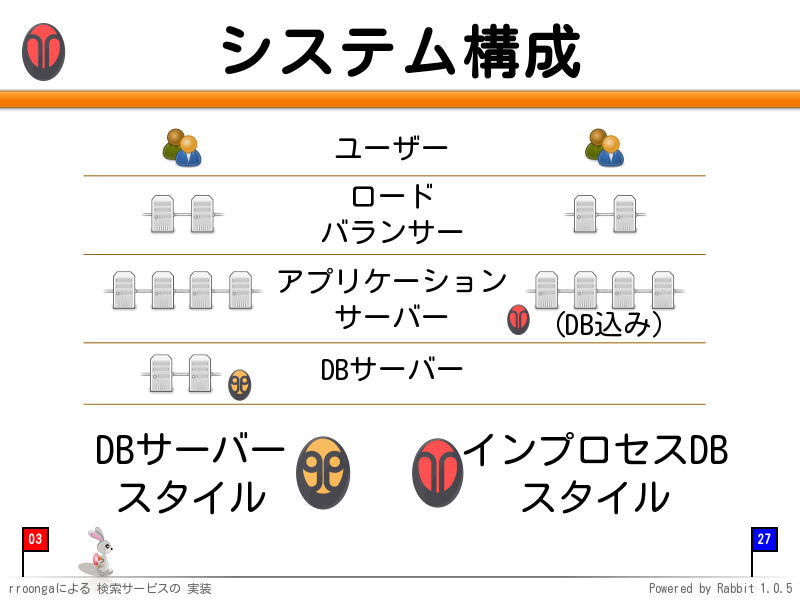
groongaをライブラリとして使う方法ではアプリケーションサーバーがデータベースを持つことになります。これは、よくあるアプリケーションサーバーとデータベースサーバーが分離している構成とは異なります。このあたりがメリット・デメリットにつながってきます。
メリット

groongaをライブラリとして使う場合、以下のようなメリットがあります。
彼らはどのように動作するか半導体、ダイオード
- 通信コストがないため、小さいコストで細かくデータを読み書きできる
- 低レベルのAPIから高レベルのAPIまで使えるため柔軟に演算を組み合わせた検索ができる
小さいコストで細かいデータの読み書きができるメリットを活かした例は後で紹介します。まずは、柔軟に演算を組み合わせられるメリットを活かした例を紹介します。
組み合わせ例: 多段ドリルダウン
組み合わせの例の1つが「多段ドリルダウン」です*1。「ドリルダウン」は「ファセット」と呼ばれることの方が多いのですが*2、ECサイトなどでよく使われている機能です。
amazon.co.jpなどで絞り込める条件がリンクになっているインターフェイスを見たことがないでしょうか。あれがドリルダウン(ファセット)です。

このスクリーンショットは「本」で検索した状態です。「本」カテゴリーのうち、さらに絞り込める項目(「コンピュータ・IT」、「ビジネス・経済」など)がリンクとしてリストされています。ここをクリックすると検索語などを入力せずに簡単に絞り込んでいくことができます。
また、各項目の横に「(5,248)」などヒット件数も表示されていることに気づいたでしょうか。これは「コンピュータ・IT」、「ビジネス・経済」などサブカテゴリーで絞り込んだ結果ヒットする件数を示しています。事前に検索システム側で検索して、0件ヒットする項目はそもそもこのリストに入らないようになっています。そのため、「絞り込んだけど0件ヒット」という無駄な検索を避けることができます。
このような点でより効率的に検索できるような機能なので、より広く使われるようになりました。

さて、多段ドリルダウンはどう違うかというと最終的な検索結果を求める途中でもドリルダウンをするという点が違います。

高レベルな検索機能しかない場合は、多段ドリルダウンを実現するために「全データ→途中結果」までの検索と「全データ→最終結果」までの検索を2回実施し、それぞれの検索結果に対してドリルダウンする必要があります。これは、高レベルな検索機能では検索の途中結果を保存しておいて再利用するような機能がないためです。
低レベルな検索機能も使えると「全データ→途中結果→ドリルダウン」をしてから「途中結果→最終結果→ドリルダウン」というように効率のよい処理を実現できます。
では、多段ドリルダウンが有用なケースはどのようなケースでしょうか。

トップ農家
多段ドリルダウンは、絞り込み後に値を変更することが多い条件に有用です。amazon.co.jpのカテゴリーの例でいえば『「コンピュータ・IT」で絞り込んだ後に、やっぱり「ビジネス・経済」に変更しよう』ということが多いかどうかということになります。多段ドリルダウンを実施しておけば「絞り込み→解除→再絞り込み」という操作ではなく「絞り込み→再絞り込み」という操作を実現でき、少ない手順で検索できます。
例えば、「価格帯」が再絞り込みをしたくなるような条件です。最初は安めの価格帯で絞り込んでいたけど、よいのがなかったからもう少し高めのものも見てみよう、ということはよくありますよね。
デメリット

デメリットはスケールアウトする標準的な仕組みがないことです。そのため、レプリケーションの仕組みを自分で作り込む必要があります。
開発事例

Rubyとgroongaでテレビ番組を検索するWeb APIを開発しています。別のシステムから提供される番組情報をrroongaを使ってgroongaのデータベースへ取り込み、番組情報を検索するためのHTTP + JSONベースのWeb APIを提供するシステムです。このシステムが直接視聴者から利用されることはなく、番組検索APIを利用した連携アプリケーションがユーザー用のインターフェイスを提供します。
このシステムは外部からの更新がないとてもシンプルな構成のため、番組情報ソースを各アプリケーションサーバーにコピーし、各サーバーでそのソースを元にデータベースを構築することで冗長化・スケールアウトを実現しています。
このAPIを利用したアプリケーションの1つがテレコ!です。地上波・BS放送・CS放送の番組をメディア横断で検索できるテレビ番組情報サービスです。ぜひ利用してみてください。
メタデータの抽出

番組検索Web APIではデータロードのときにもrroongaが活躍しています。その1つがメタデータの抽出処理です。
メタデータはドリルダウン条件として使えるため検索しやすいシステムを構築するためには重要な情報になります。番組情報の場合は出演者やカテゴリなどがメタデータとなります。メタデータは重要な情報なのですが、用意するにはそれなりの手間がかかるため、なかなか充実させることができません。そのため、ある程度機械的に抽出することで補うことが有効です。番組検索Web APIでは以下のようなコードで番組説明から出演者情報を抽出しています。
トラベルトレーラーの電源コードを配線し直す方法
1 2 3 4 5 6 7 8 9 10 11 | names = [] # 番組説明 description = "出演者: ビートたけし・所ジョージ" # 人物テーブル people = Groonga["People"] # people.records -> ["ビートたけし", "明石家さんま"] people.scan(description) do |record,| # 番組説明内に人物テーブル内の人物名があったら抽出 names << record.key # "ビートたけし" end p names # -> ["ビートたけし"] |
やっていることは「はてなダイアリーでのキーワード自動リンク」と同じことです。テキスト(番組説明)中から事前に用意した語(人物名)を抽出しています。なお、この処理のことを「multiple string matching」と呼ぶそうです。
これはgroongaの低レベルのAPIを使って実現します。ただ、この処理のときはデータベース内のデータを頻繁に参照することになるので、データロードするアプリケーションがデータベースを持っていないと時間がかかって実用的にはならないでしょう。
入力補完
最後に入力補完の実現方法について説明します。

groonga本体にはサジェスト機能があり、この機能は以下の機能を提供します。
- 補完: 一部分を入力するだけで完全な検索語を入力できるようにする機能(Googleの検索ボックスにもある機能)
- 補正: 検索語の一部が間違っていても修正して正しい検索語にする機能(Googleでいえば「もしかして」機能)
- 提案: 検索結果が多いときに絞り込み用の追加の検索語を提示する機能(Googleでいえば「他のキーワード」機能)
- ユーザーの入力から統計的に学習し↑の3つを強化する機能
このうち補完機能を使った入力補完の実現方法について説明します。

groongaの補完機能は補完候補そのものの字面(例えば「万葉集」が補完候補なら「万」など)でなくても、ローマ字やひらがな・カタカナで入力しても補完候補を提示できます。これはIMEがOFFの状態でも利用できて日本語を利用した検索システムではとても便利です。Googleでも同様のことをできますが、amazon.co.jpではできないようです。

補完方法には大きく分けて以下の2つの方法があります。
- コンテンツベースの方法
- 統計情報ベースの方法
コンテンツベースの方法ではすでにデータベース内にある既知の情報を補完候補とする方法です。番組検索Web APIの場合は番組名や人物名などが適切な補完候補になります。この方法ではデータベース内にある正しい補完候補のみを利用するので、間違った候補を出すことがないというメリットがあります。一方、候補数が少なくて思ったより補完してくれないということもありえます。例えば、「コナ」では「名探偵コナン」を補完してくれなくて「名探偵」と入力しないといけない、といったことがあります。
統計情報ベースの方法ではユーザーの検索履歴をアクセスログなどから収集・解析し、多くのユーザーが検索した語などを補完候補とします。この方法では「コナ」で「コナン」を補完候補とできる可能性があります。一方、ある程度の統計情報がないと適切な補完候補を抽出できなかったり、補完候補の精度が低くなってしまう可能性もあり、調整が必要になります。例えば、特定のキーワードをわざと多く検索してくるようなアクセスがあった場合はそのようなアクセスを無視するといったことが必要になるかもしれません。
まとめ

rroongaを使った検索システムの構成とその構成ならではのメリットとデメリットを紹介しました。メリットはメタデータの抽出などgroongaの低レベルのAPIも利用しながら検索システムを構築できることです。デメリットは標準的なレプリケーションの仕組みがないため冗長化やスケールアウトの仕組みを自作する必要があることです。
また、rroongaを使った検索システムの構成とは関係ないのですが、入力補完の実現方法についても紹介しました。
お知らせ

groongaの開発元である有限会社未来検索ブラジルとMySQLからgroongaを使うためのソフトウェアmroongaの開発に参加している斯波さんとクリアコードでgroongaのサポートサービスを提供することにしました。サポート開始は2/29の予定ですがすでにお問い合わせは受け付けていますので、groongaサポートサービスに興味のある方はぜひお問い合わせフォームからご連絡ください。
0 件のコメント:
コメントを投稿